I gave my AI workspace the ability to file bug reports against itself
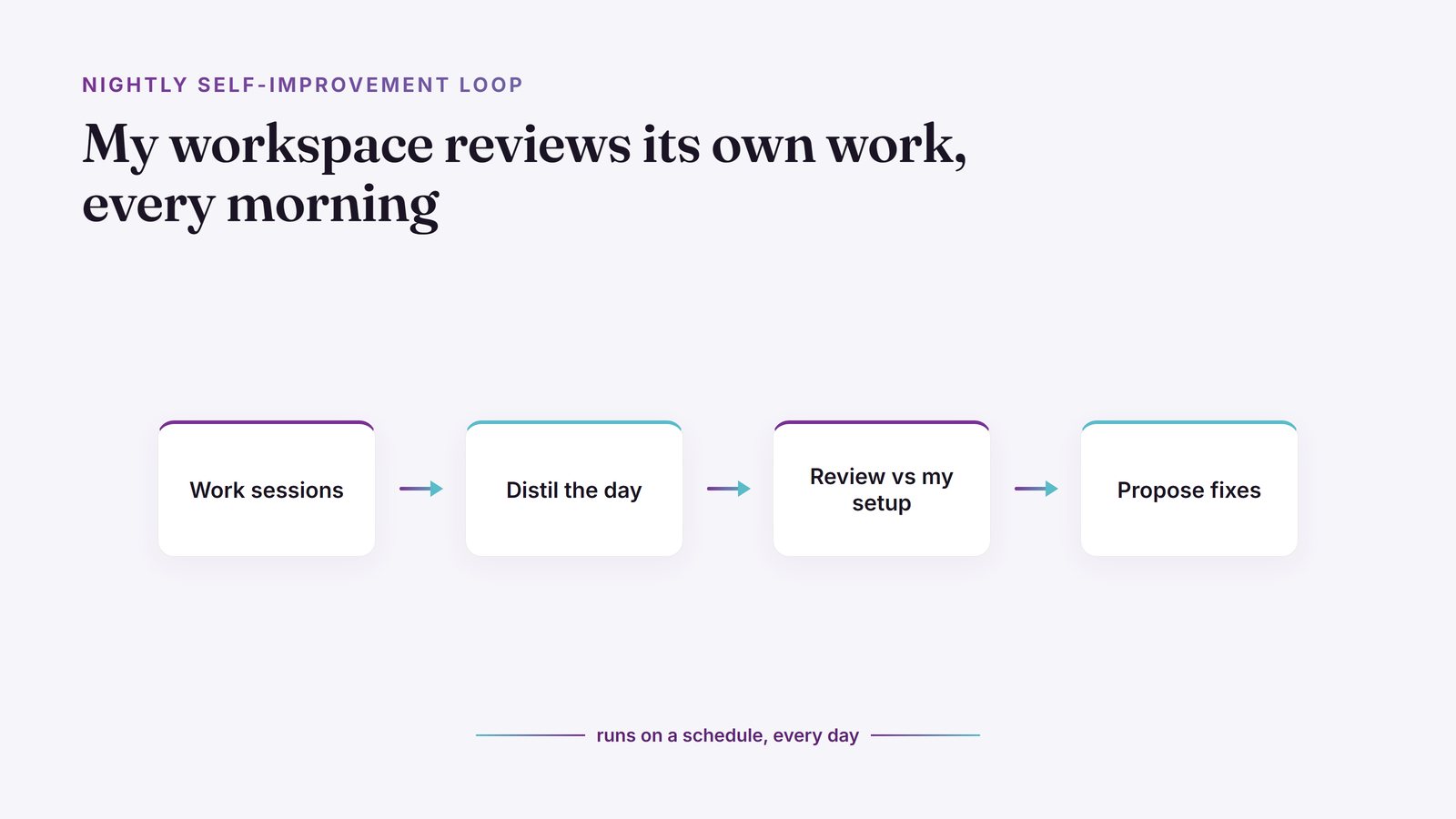
Every night a scheduled job reads back my own work sessions, spots where my tools tripped me up, and proposes fixes to its own setup. Here is how the loop works.
Key takeaways
- I run a one-person business out of an AI workspace, so the quality of that workspace is the quality of my output.
- A scheduled job reads back yesterday's work sessions every morning and looks for where my own tools slowed me down.
- It writes a concrete improvement report: which skill, rule, or script to change, and why.
- It proposes, it does not apply. I stay in the loop on every change.
- The system gets a little better every day without me having to remember what went wrong.
Most of my business runs through an AI workspace. It drafts, it builds, it researches, it keeps track of clients. So the quality of that workspace is, more or less, the quality of what I ship.
The problem with a workspace you use that hard is that it accumulates small frictions. A skill that asks the wrong question. A rule that fires when it should not. A script that fails the same way twice. None of them are worth stopping to fix in the moment, so they never get fixed.
So I built a loop that fixes them for me. Every morning, before I start, my workspace files bug reports against itself.
What it actually does
A scheduled job reads back yesterday's work sessions, finds where my own tools slowed me down, and writes a report proposing specific fixes to the skills, rules, and scripts I use. It proposes; I decide.
The loop runs in two stages. First, a scheduled job wakes up every morning and distils the previous day's work sessions into a clean digest: what I asked for, what the tools did, and where it took more tries than it should have.
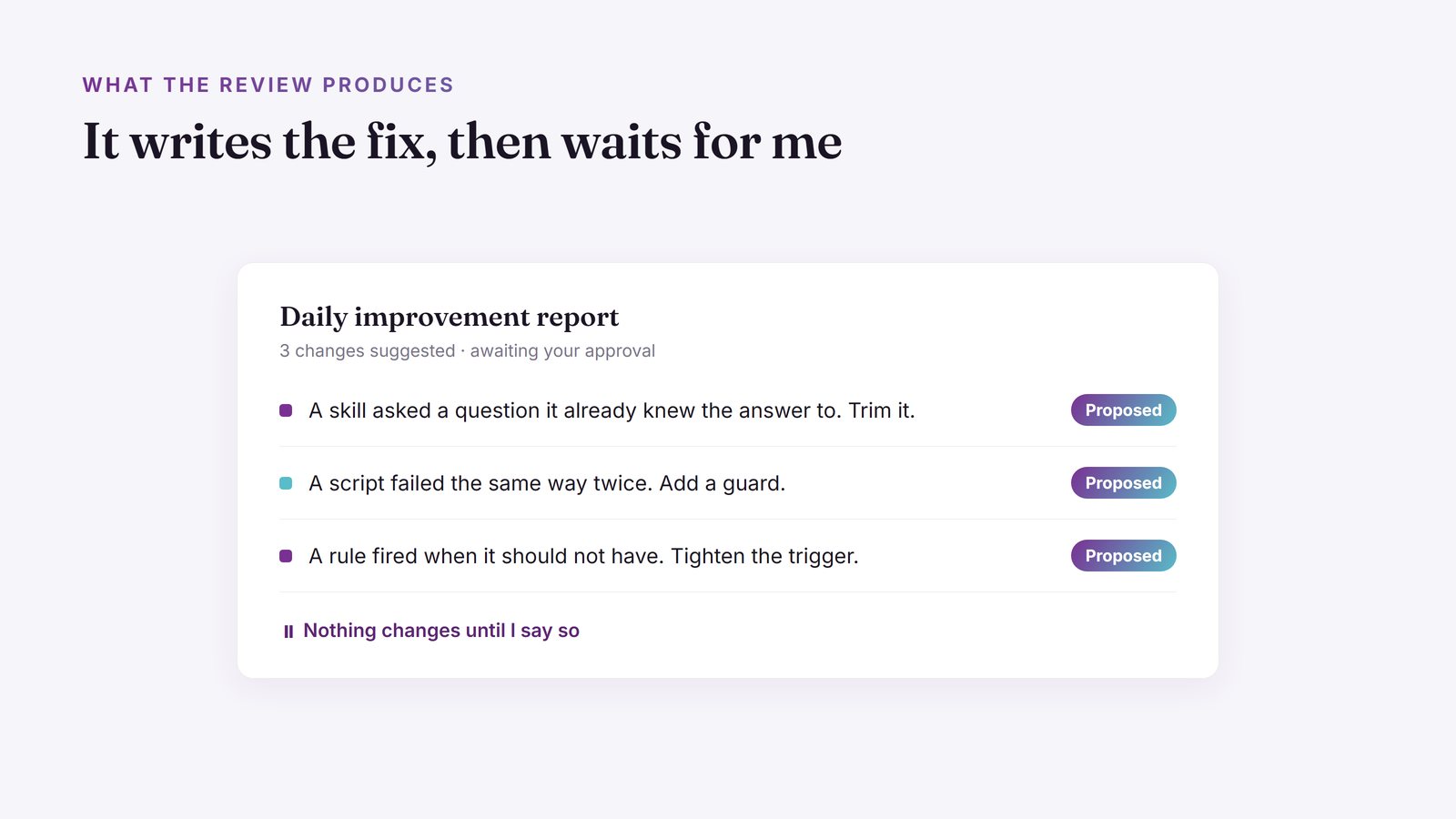
Then a reviewer reads that digest with one question in mind: what about my setup made this harder than it needed to be? It compares the friction against my actual configuration, the skills and rules and scripts that run the workspace, and writes a concrete improvement report. Not "be better", but "this skill asked a redundant question, here is the line to change."
I built it on top of Claude Code, which keeps a transcript of every session. Without that transcript there is nothing to review. The transcript is the raw material.
The one rule that makes it safe
The reviewer proposes changes. It never applies them. A human reads every recommendation before anything in the workspace changes.
This is the part I will not compromise on. It would be easy to let the agent close the loop itself: spot the problem, rewrite the rule, move on. It would also be how you end up with a workspace that quietly drifts into something you no longer understand or trust.
So the reviewer writes recommendations and stops. I read them over coffee and pick what to apply. The compounding still happens, just with me as the final gate.

The system gets a little better every day, and I never have to remember what went wrong.
Why this matters more than it sounds
A single fix is nothing. The point is the compounding. A workspace that improves one small thing a day is a different tool in three months, and I did not have to hold any of it in my head.
It also changed how I feel about friction. A tool tripping me up used to be annoying. Now it is just tomorrow's report. The annoyance has somewhere to go.
This is the same workspace I build client systems in, like the AI assistant I gave my dad's painting business. The better the workspace gets, the better that work gets too. That is the real reason I bother.
If your work already runs through something that keeps a transcript, you can build the same loop. A scheduled job, a step that distils the day, a reviewer that compares it against your setup. The plumbing is simple. The discipline is being honest in the review.
Frequently asked questions
Does the AI change its own code automatically?
No. The reviewer proposes fixes in a report. I read them and decide what to apply. Letting an agent silently rewrite its own rules is how you wake up to a workspace you no longer understand. The human stays in the loop on every change.
What does it actually look at?
It reads back the work sessions from the day: what I asked for, what the tools did, where things went wrong or took too many tries. Then it pattern-matches that against my skills, rules, and scripts to find the weak link.
Why not just fix things as they break?
Because I forget. In the moment I am trying to ship the actual task, not log that a tool tripped me up. The nightly review catches the lessons I would otherwise lose, and turns a vague annoyance into a specific change.
Could I build this for my own work?
Yes, if your work already runs through a tool that keeps a transcript. The pattern is simple: a scheduled job, a step that distils the day, and a reviewer that compares it against your setup and writes recommendations. The hard part is being honest in the review, not the plumbing.